简单阅读 DeepEP
2月26日•5min
为了追求极致性能,我们发现并使用了一个文档之外的 PTX 指令:ld.global.nc.L1::no_allocate.L2::256B。这条指令会导致未定义行为:使用非一致性只读PTX修饰符.nc访问易失性GPU内存。但是,在 Hopper 架构上,经过测试,使用 .L1::no_allocate 可以保证正确性,并且性能会好得多。
但实际上 no_allocate 这个指令其实文档中是有的(详见文档214页),但是只是草草说了句用途,并没有详细解释能带来什么提升。
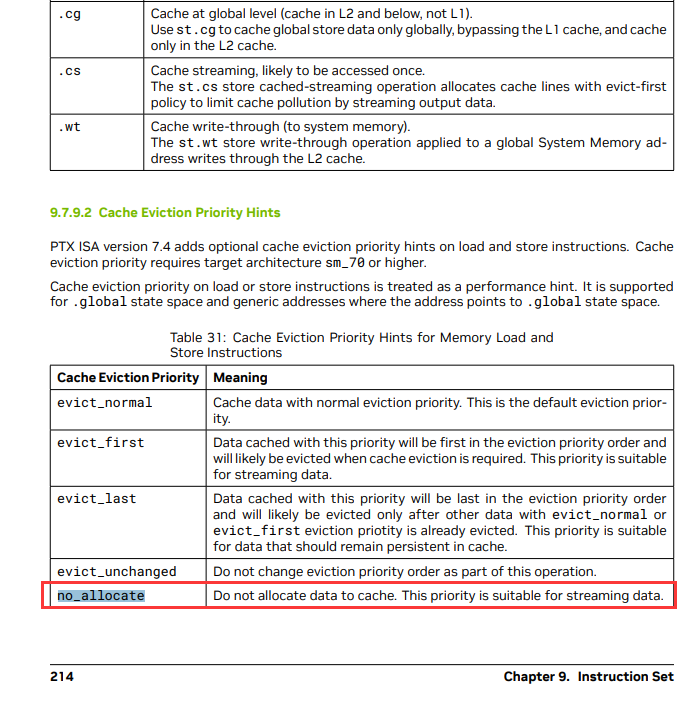
由此可见 DeepSeek 对 CUDA 的研究程度之深,以及在GPU领域的积累。
觉得传统码农被代替,是不是写 CUDA 有出路的同学可以试着啃一啃这个734页的 CUDA PTX ISA 文档。总比3000页的 x86 文档好啃,对吧😇
CUDA PTX ISA 文档:CUDA PTX ISA
CC BY-NC-SA 4.02022-PRESENT © Elone Hoo